

راه اندازی HA دسترسی بالا در VMware vSphere
راه اندازی HA دسترسی بالا در VMware vSphere، هنگامی که در یک محیط مجازی، عناصر مهمی مانند ماشین های مجازی وجود دارد که سرویس های حیاتی روی آن ها در حال اجرا هستند، در دسترس بودن آن ها باید در زمان های عملیاتی سازمان شما تضمین شود. یکی از راه های دستیابی به دسترسی بالا (HA)، استفاده از یک کلاستر جهت اطمینان از اجرای مداوم سرویسها و برنامه ها می باشد. پلتفرم مجازی سازی VMware vSphere این امکان را فراهم می کند تا از یک کلاستر جهت اجرای ماشین های مجازی (VM) و استفاده از vSphere High Availability (HA) جهت دسترسی بالا استفاده نمود. در این مقاله قصد داریم به قابلیت HA و نحوه راه اندازی آن در VMware vSphere بپردازیم.
راه اندازی HA دسترسی بالا در VMware vSphere
فهرست مطالب
HA چیست
دسترسی بالا (HA) در VMware vSphere دسترسی بهینه را جهت ماشین های مجازی و سایر مولفه های مرتبط با آن ها از جمله برنامه ها و سرویس های در حال اجرا بر روی ماشینهای مجازی را فراهم می نماید تا در صورت خرابی، زمان خرابی را به حداقل کاهش یابد. دسترسی بالا (HA) قابلیتی است که توانایی یک محیط مجازی جهت مقاومت در برابر خرابی میزبان را امکان پذیر می نماید و یکی از دلایل مهمی است که می بایست VMware vCenter و یک کلاستر را به جای میزبان VMware ESXi مستقل انتخاب نمود.
هنگامی که HA بر روی یک کلاستر اجرا می شود، یک Agent بر روی هر میزبانی که در کلاستر شرکت دارد نصب می گردد. هر agent در میزبان ها با دیگری ارتباط برقرار نموده و دسترسی میزبان ها در کلاستر را از طریق مکانیزم heartbeat نظارت می نمایند. اگر به مدت 15 ثانیه ای heartbeat از یک میزبان خاص بدون پاسخ باشد و پینگ به میزبان نیز انجام نشود، میزبان به عنوان Fail در نظر گرفته خواهد شد.
HA با پایش سلامت سخت افزار میزبان به طور فعال VM ها را از میزبان هایی که مشکلات سختافزاری دارند، به میزبان های جدیدی منتقل خواهد نمود.
پیشنیاز ها
جهت ایجاد یک کلاستر با قابلیت HA چند الزام وجود داردکه عبارتند از:
- میزبان ها در کلاستر HA می بایست لایسنس مورد نیاز را داشته باشند. لایسنس های vSphere Standard یا Enterprise Plus به همراه vCenter Standard می بایست در نظر گرفته شده باشد.
- جهت فعال سازی HA حداقل دو میزبان مورد نیاز می باشد. سه میزبان و بیشتر توصیه می شود.
- پیکربندی میزبان ها با آدرس های IP ثابت (Static).
- دسترسی به حداقل یک شبکه مدیریت (management) مشترک بین میزبان ها.
- با توجه به اینکه ماشین های مجازی بین میزبان های یک کلاستر جا به جا خواهند شد، جهت اینکه ماشین های مجازی در تمام میزبانها اجرا شوند می بایست این میزبان ها به منابع شبکه و فضای ذخیره سازی اشتراکی (Shared Datastore) مشابهی دسترسی داشته باشند.
- فضای ذخیرهسازی مشترک.
- Tools VMware می بایست بر روی ماشین های مجازی که در HA پایش می شوند اجرا شود.
مکانیزم تشخیص خرابی
سوالی که مطرح می گردد این است که در HA چگونه خرابی را بین میزبان های موجود در کلاستر را تشخیص می دهد. در پاسخ می توان به مکانیزم Heartbeats اشاره نمود. این Heartbeat ها امکان ارسال و دریافت از عناصر شبکه و همچنین Datastore را دارند. چنانچه یک ماشین مجازی با کمک HA قصد انتقال به میزبان ESXi دیگری را داشته باشد استفاده از فضای ذخیره سازی اشتراکی بین میزبان ها و قرارگیری ماشین های مجازی بر روی این دسته از Datastore ها از اهمیت ویژه ای برخوردار می باشد. چرا که اگر یک ماشین مجازی بر روی دیسک Local یک میزبان ESXi قرار داشته باشد حتی اگر HA بر روی کلاستر فعال باشد، اگر میزبان مورد نظر با مشکل مواجه شود انتقال ماشین های مجازی روی آن انجام نخواهد گرفت و می بایست ماشین های مجازی بر روی یک Datastore اشتراکی قرار داشته باشند. در چنین شرایطی هر میزبان جهت اطمینان از صحت عملکرد Datastore با ارسال heartbeat این فرایند را انجام خواهد داد. چنانچه میزبان های ESXi به واسطه مکانیزم Heartbeat نتوانند با یکدیگر در شبکه ارتباط برقرار نمایند اما دسترسی و Heartbeat به سمت Datastore را داشته باشند در این شرایط Isolation اتفاق می افتد. بدین صورت که ارتباط بین میزبان های ESXi برقرار نیست اما دسترسی به دیتا استور اشتراکی امکان پذیر می باشد. در چنین شرایطی پینگ به سمت آدرس Isolation نیز ارسال می گردد که در ادامه به آن خواهیم پرداخت.
بنابراین به صورت کلی دو Heartbeat برای شبکه و Datastore خواهیم داشت. مکانیزم Heartbeat شبکه بدین صورت است که، یکی از میزبان های ESXi در کلاستر به عنوان میزبان Primary جهت HA انتخاب شده و مابقی میزبان های درون کلاستر نیز Secondary خواهند گردید. سپس میزبان Primary اقدام به ارسال Heartbeat به سمت میزبان های Secondary می نماید و میزبان های Secondary نیز به آن پاسخ خواهند داد. در نهایت Primary وضعیت را به vCenter گزارش می دهد. در آخر نیز vCenter تصمیم خواهد گرفت که آیا ماشین مجازی جا به جا شود یا خیر. اگر میزبانی که به عنوان Primary انتخاب شده پاسخی از میزبان های Secondary درون کلاستر دریافت نکند، در این شرایط ابتدا Primary ارسال های Heartbeat از میزبان مورد نظر به سمت Datastore را چک می کند اگر Heartbead های میزبان Secondary مورد نظر بر روی Datastore وجود داشته باشد در چنین شرایطی حتی اگر این میزبان به Heartbeat های شبکه پاسخ نداده باشد به عنوان یک میزبان فعال در نظر گرفته می شود. این حالت نشان دهنده حالت Isolation می باشد و بنا به سیاست در نظر گرفته جهت رخداد Isolation سرور vCenter اقدامات لازم را انجام خواهد داد.
در سناریویی دیگر فرض کنیم که میزبان Primary ابتدا یک Heartbeat شبکه به سمت میزبان های درون کلاستر ارسال می نماید و به عنوان مثال میزبان ESXi-1 به آن پاسخی نمی دهد. در مرحله بعد با چک کردن Heartbeat های ثبت شده بر روی Datastore از عدم ثبت Heartbeat این میزبان بر روی Datastore نیز اطمینان حاصل می نماید. در مرحله بعدی آدرس IP میزبانی که به Heartbeat ها پاسخ نداده توسط Primary پینگ خواهد گردید. این سه کار در فرایند تشخیص میزبان خارج از دسترس انجام خواهد شد. اگر میزبان در تمامی این سه فرایند ها Fail شود به عنوان یک میزبان خراب در نظر گرفته خواهد شد و با توجه به سیاست های در نظر گرفته شده برای این شرایط vCenter اقدام خواهد نمود. اگر حالت Nothing انتخاب شده باشد در چنین شرایطی و در هنگام تشخیص یک میزبان خراب vCenter هیچ اقدامی جهت جا به جایی ماشین های مجازی موجود بر روی این میزبان نخواهد داشت. اگر Restart VMs انتخاب شده باشد در این شرایط ماشین های مجازی بر روی میزبان دیگری مجدد بالا خواهند آمد. همچنین امکان اعمال اولویت بر روی ماشین های مجازی وجود دارد تا ماشین های مجازی که نقش مهمی در شبکه ایفا می کنند با اولویت بالاتر و اول بر روی میزبان دیگری مجدد راه اندازی (Restart) شوند.
در HA یک آدرس IP به عنوان Isolation Address نیز در نظر گرفته می شود. معمولا از آدرس Default Gateway برای Isolation Address استفاده می گردد. در شرایطی که یک میزبان های Secondary پیام های Heartbeat از سمت Primary دریافت نکنند Isolation Address را پینگ می نمایند. البته باید در نظر داشت در شبکه های سازمانی در اکثر مواقع Default Gateway پاسخ پینگ را بر نمی گرداند چرا که اکثر فایروال ها طوری تنظیم می شوند تا به پینگ های ارسالی پاسخی ندهند. همچنین این امکان وجود دارد تا چند Isolation Address را تنظیم نماییم تا در صورتی که یکی از آن ها پاسخگو نبود دیگری امکان پاسخگویی به پینگ های ارسالی را داشته باشد.
پیاده سازی HA
چنانچه قصد استفاده از قابلیت HA در محیط VMware vSphere را داریم ابتدا می بایست آن را فعال نماییم. جهت فعال سازی HA در کنسول مدیریت vCenter کلاستر مورد نظر را انتخاب و از تب های در درسترس بر روی Configure کلیک می کنیم. در این تب در منوی سمت چپ گزینه vSphere Availability را انتخاب می نماییم. در پنجره باز شده بر روی Edit کلیک نموده و با کلیک بر روی دکمه vSphere HA این قابلیت را فعال می کنیم. تب Failures and Responses جهت پیکربندی رفتار یک کلاستر HA و تنظیم کارهایی که باید با ماشین های مجازی در موقعیت های مختلف انجام شود استفاده می گردد.
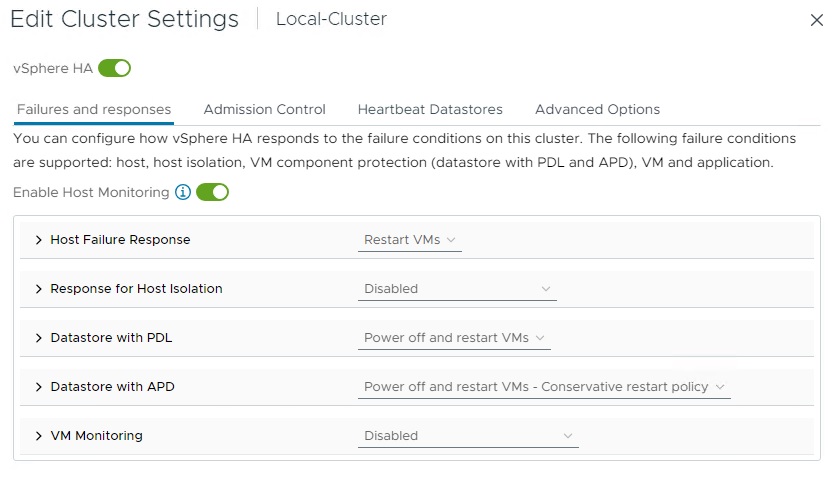
با فعال نمودن Host Monitoring، میزبان های ESXi درون کلاستر اقدام به تبادل Heartbeat خواهند نمود. در هنگام Maintenance و انجام تعمیرات، بهتر است این گزینه غیر فعال شود تا از مهاجرت های ناخواسته ماشین های مجازی جلوگیری شود.
گزینه Host Failure Response
از این گزینه جهت تنظیم نحوه واکنش یک کلاستر HA به شرایط خرابی استفاده می شود. که دو حالت در درسترس می باشد.
- Disabled: در این حالت مانیتورینگ میزبان ESXi خاموش است و چنانچه خرابی رخ دهد هیچ واکنشی وجود نخواهد داشت.
- Restart VMs: ماشین های مجازی در صورت خرابی میزبان به ترتیب تعیین شده مجددا راه اندازی می شوند.
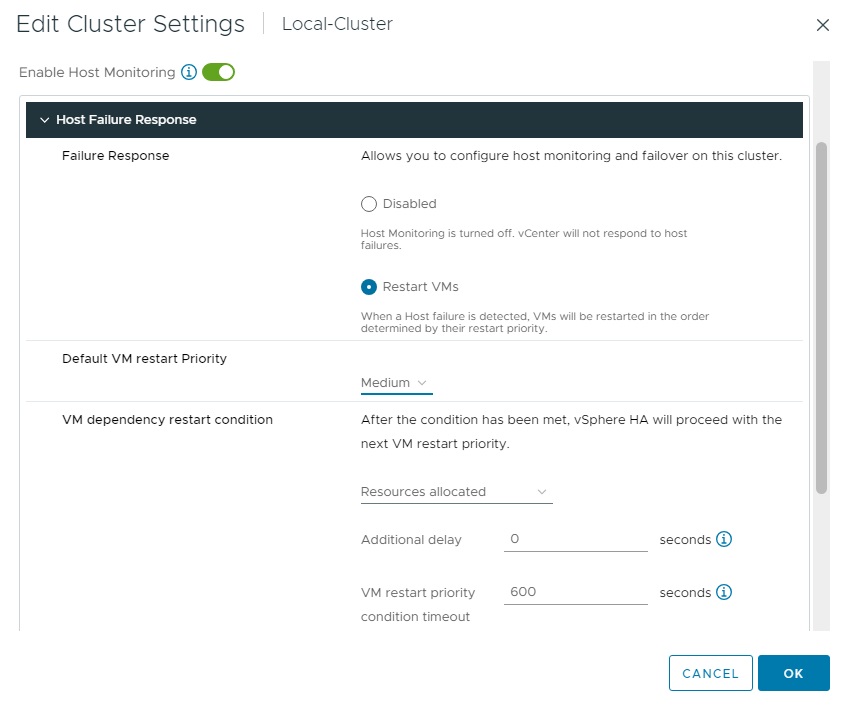
تنظیم دیگری که در Host Failure Response قابل اعمال می باشد، Default VM restart Priority است. این تنظیم برای تعیین اینکه کدام گروه VM باید ابتدا و با اولویت راه اندازی مجدد شود استفاده می شود. پنج اولویت (Lowest, Low, Medium, High, Highest) در این قسمت وجود دارد. البته این امکان وجود دارد صرفا برای یک ماشین مجازی خاص که از اهمیت ویژه ای برخوردار است از یک اولویت بالاتر و به صورت مخصوص صرفا برای همان ماشین مجازی استفاده نمود. اما این قسمت به صورت کلی و گروهی به ماشین های مجازی یک اولویت اعمال می نماید. به صورت پیش فرض نیز گزینه Medium انتخاب شده است.
در قسمت VM dependency restart condition می توان شرطی را انتخاب نمود که با برآورده شدن آن، یک کلاستر تشخیص دهد که ماشین های مجازی با موفقیت مجددا راه اندازی شده اند. در این قسمت چهار شزط وجود دارد:
- Resources Allocated
- Powered On
- Guest Heartbeats detected
- App Heartbeats detected
گزینه Response for Host Isolation
گزینه Host Isolation Response این امکان را می دهد که رفتار کلاستر HA را در زمانی که یک میزبان ESXi به کار خود ادامه می دهد اما اتصالات شبکه مدیریتی را از دست داده مشخص نماییم. در حالت پیش فرض Disabled می باشد و در چنین حالتی هیچ واکنشی نشان نخواهد داد. گزینه های Power off and restart VMs و Shut down and restart VMs نیز در این قسمت وجود دارد که تفاوت Power off و Shutdown در این است که در حالت Power off به مانند این است که یک سیستم را از برق جدا کرده باشیم. اما در حالت Shutdown ابتدا سیستم عامل ماشین مجازی به صورت درست خاموش شده و سپس ماشین مجازی مورد نظر بر روی میزبان دیگری مجدد روشن و راه اندازی خواهد شد.
گزینه Datastore with PDL
این گزینه مربوط به شرایطی است که میزبان ESXi دسترسی به یک Datastore را به صورت دائمی غیر ممکن در نظر می گیرد. به عنوان مثال یک عنصر مثل Adapter که جهت دستیابی به یک Datastore مورد استفاده قرار می گیرد به صورت کامل Fail شده باشد. در این شرایط سه واکنش وجود دارد:
- Disabled: هیچ واکنشی انجام نخواهد گرفت.
- Issue events: یک Event ایجاد می شود.
- Power off and restart VMs: ماشین مجازی مورد نظر Power off شده و بر روی میزبان دیگر مجدد را اندازی شود که در حالت پیش فرض این گزینه در نظر گرفته شده است.
گزینه Datastore with APD
شرایطی است که به یک کلاستر اجازه میدهد زمانی که همه مسیرها Down هستند، و هیچ نشانهای از موقت یا دائمی بودن Loss دستگاه وجود ندارد، پاسخ دهد. چهار گزینه برای این تنظیم موجود است:
- Disabled: هیچ واکنشی انجام نخواهد گرفت.
- Issue events: یک Event ایجاد می شود.
- Power off and restart VMs: ماشین مجازی مورد نظر Power off شده و بر روی میزبان دیگر مجدد را اندازی شود که در حالت پیش فرض این گزینه در نظر گرفته شده است.
- Shutdown and restart VMs: ماشین مجازی مورد نظر Shutdown شده و بر روی میزبان دیگر مجدد را اندازی شود.
گزینه VM Monitoring
با استفاده از Tools VMware که روی ماشین های مجازی اجرا میشوند، پایش ماشین مجازی با استفاده از مکانیزم Heartbeat فعال خواهد شد. همچنین می توان با استفاده از این قابلیت نظارت بر برنامه را نیز پیکربندی نمود. چنانچه Heartbeat مربوط به یک VM به موقع دریافت نشود، راه اندازی مجدد VM آغاز می شود. در حالت پیش فرض این گزینه غیر فعال می باشد.
تب Heartbeat Datastores
همانطور که پیشتر گفته شد هر میزبان ESXi یک Heartbeat به Datastore ارسال می نماید. در تب Heartbeat Datastores می توان یک Datastore خاص را جهت انجام این فرایند مشخص نمود. این کار به صورت خودکار انجام می گیرد اما اگر قصد داریم یک Datastore خاص در این فرایند مورد استفاده قرار گیرد در این تب این امکان فراهم می گردد.

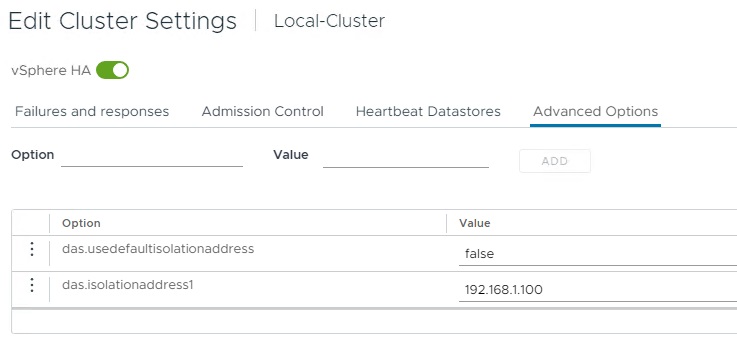
در تب Advanced Option امکان قرار دادن اطلاعات و تنظیمات خاص در دسترس قرار خواهد گرفت. به عنوان مثال هنگامی که قصد داریم از isolation Addressپیش فرض استفاده نکنیم در این قسمت این کار انجام خواهد گرفت. در این قسمت قصد داریم از آدرس IP مربوط به سرور به عنوان Isolation Address استفاده نماییم بنابراین در تب Advanced Option مطابق تصویر زیر عمل خواهیم نمود. در خط استفاده از Isolation Address پیش فرض را در حالت False قرار می دهیم و در خط دوم Isolation Address مورد نظر را وارد خواهیم نمود.
با انجام تنظیمات فوق HA بر روی کلاستر مورد نظر فعال خواهد شد و چنانچه کلاستر مورد نظر را انتخاب و بر روی تب Monitor کلیک نماییم اکنون یک قسمت با عنوان vSphere HA اضافه گردیده است. اما پس از یادگیری مفاهیم HA و نحوه پیکربندی آن در VMware vSphere می بایست از صحت عملکرد آن نیز مطمئن گردید. جهت تست سه ماشین مجازی که بر روی یک میزبان ESXi قرار دارند را در نظر می گیریم. این ماشین های مجازی بر روی datastore های اشتراکی نیز قرار دارند. با توجه به فعال بودن DRS و HA چنانچه مشکلی برای میزبانی که ماشین های مجازی بر روی آن قرار دارند پیش آید، ماشین های مجازی می بایست در میزبان دیگر مجدد راه اندازی شوند. در این سناریو ماشین های مجازی بر روی میزبان 192.168.1.101 قرار دارند. به عنوان مثال یکی از ماشین های مجازی را مشاهده می نماییم که بر روی میزبان 192.168.1.101 قرار دارد.
حال پیش از اینکه HA را مورد ارزیابی قرار دهیم فرض کنید قصد داریم VM-1 که سرویس حیاتی بر روی آن است پیش از ماشین های مجازی دیگر روشن و شروع به سرویس دهی نماید. همانطور که قبلا گفته شد به صورت پیش فرض اولویت ماشین های مجازی برای HA در حالت Medium قرار دارد. حال برای آن که یک ماشین مجازی را با اولویت بالاتری قرار دهیم می بایست کلاستر مورد نظر را انتخاب و بر روی تب Configure کلیک نماییم. در قسمت Configuration در ستون سمت چپ گزینه VM Overrides را انتخاب می کنیم. حال بر روی ADD کلیک می کنیم. در پنجره باز شده ماشین مجازی مورد نظر (VM-1) را انتخاب و بر روی Next کلیک می کنیم.
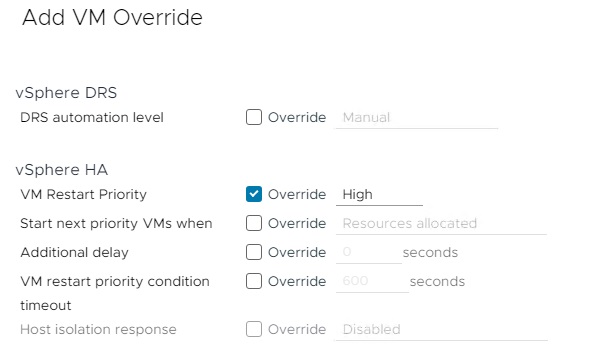
در پنجره بعدی می توان بسیاری از تنظیمات یک ماشین مجازی را شخصی سازی و Override نمود. در این قسمت قصد داریم اولویت ماشین مجازی مورد نظر را در HA بالاتر ببریم، بنابراین در قسمت vSphere HA گزینه VM Restart Priority را فعال نموده و آن را گزینه ای بیش از Medium (High یا Highest) قرار می دهیم.
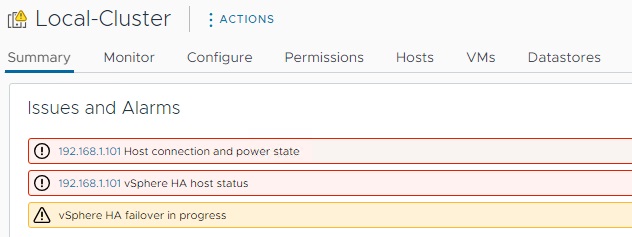
حال می بایست شرایطی را ایجاد کنیم تا میزبان ESXi به طور دستی خراب محسوب گردد. به همین منظور به عنوان آزمایش میزبان ESXi را خاموش می کنیم. در این حالت vCenter شروع به نمایش هشدار های مربوط به HA خواهد نمود.
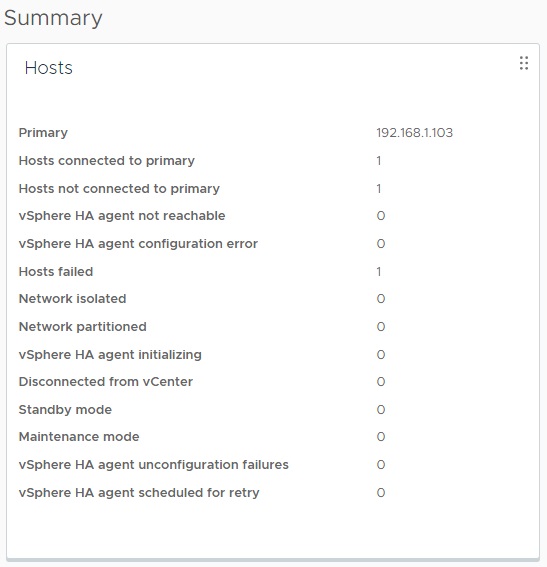
همانطور که مشاهده می نمایید با خاموش شدن میزبان ESXi فرایند HA شروع شده و ماشین های مجازی پس از مدت زمانی به واسطه DRS به میزبان های دیگر منتقل خواند شد و در آن جا مجدد راه اندازی می گردند. اکنون چنانچه کلاستر مورد نظر را انتخاب و تب Monitor را انتخاب کنیم در قسمت vSphere HA می توان در قسمت Summary یک خلاصه از وضعیت سیستم را مشاهده نماییم که با توجه به اینکه یکی از میزبان های ESXi را خاموش نمودیم، اکنون عدد 1 در قسمت Host failed نمایش داده خواهد شد.
در محیط vSphere ، قابلیت های HA و DRS جهت محافظت در برابر خرابی میزبان ها و همچنین تعادل بار کاری و زمانبندی منابع مورد استفاده قرار می گیرند. در محیط هایی با مقیاس گسترده جهت تداوم کسب و کار و دستیابی به دسترسی بالا می بایست استفاده از این قابلیت ها را همواره در دستور کار قرار داد. باید توجه داشت که حتی اگر ماشین های مجازی در کلاستر در حال اجرا هستند، پشتیبان گیری از ماشین های مجازی به صورت دوره ای نجام گیرد تا از دست رفتن داده ها جلوگیری شود.




























نظرات کاربران